I built a self-hosted transcription and search engine for everything I listen to.
Accurate speaker labels, chapters, full-text search, and an MCP server so Claude can query the whole thing.
I listen to a lot of long interview podcasts and can't remember most of the second-order details a week later. Not all podcasts have a transcript readily available. Manual transcription is time-consuming and wasteful, often isn't accurate enough with multiple speakers, or it keeps the text locked inside someone else's app where I can't search it.
So I built my own. It runs on my own machine, the transcripts are mine, and I can do whatever I want with them — search across years of episodes, or hand the whole library to Claude and ask grounded questions with citations. A Buffett answer from a 1996 annual meeting surfaces right next to a 2026 podcast on the same query; that compounding across decades is the part I actually use.
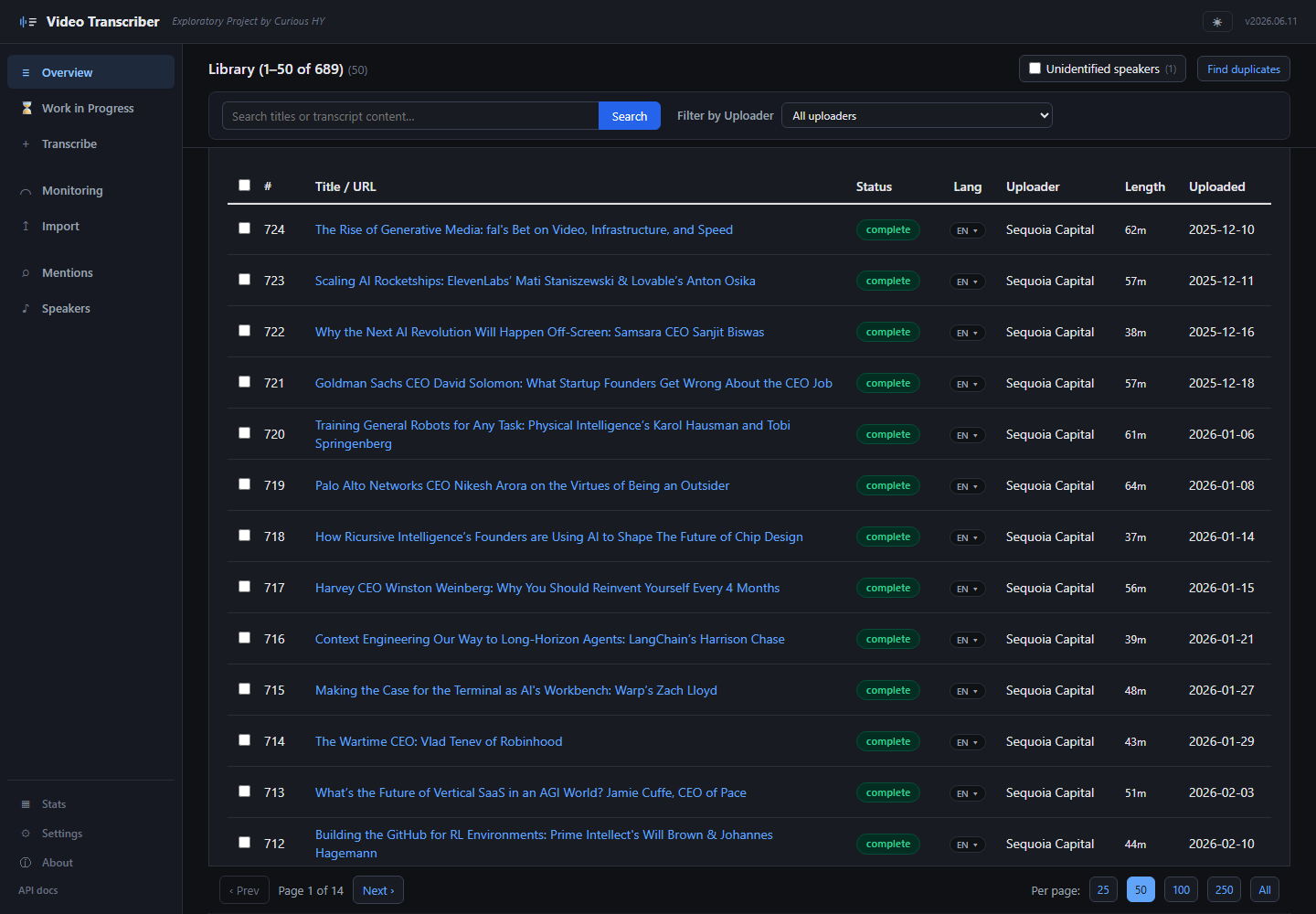
It's a personal tool, not a product — no sign-up, no hosted instance, and it's not going to grow into one. It has already processed hundreds of episodes and is still growing. I use it very often, and the database of knowledge keeps compounding. Here's a look, with what it does and how it's built below; the rest of the screenshots are further down.
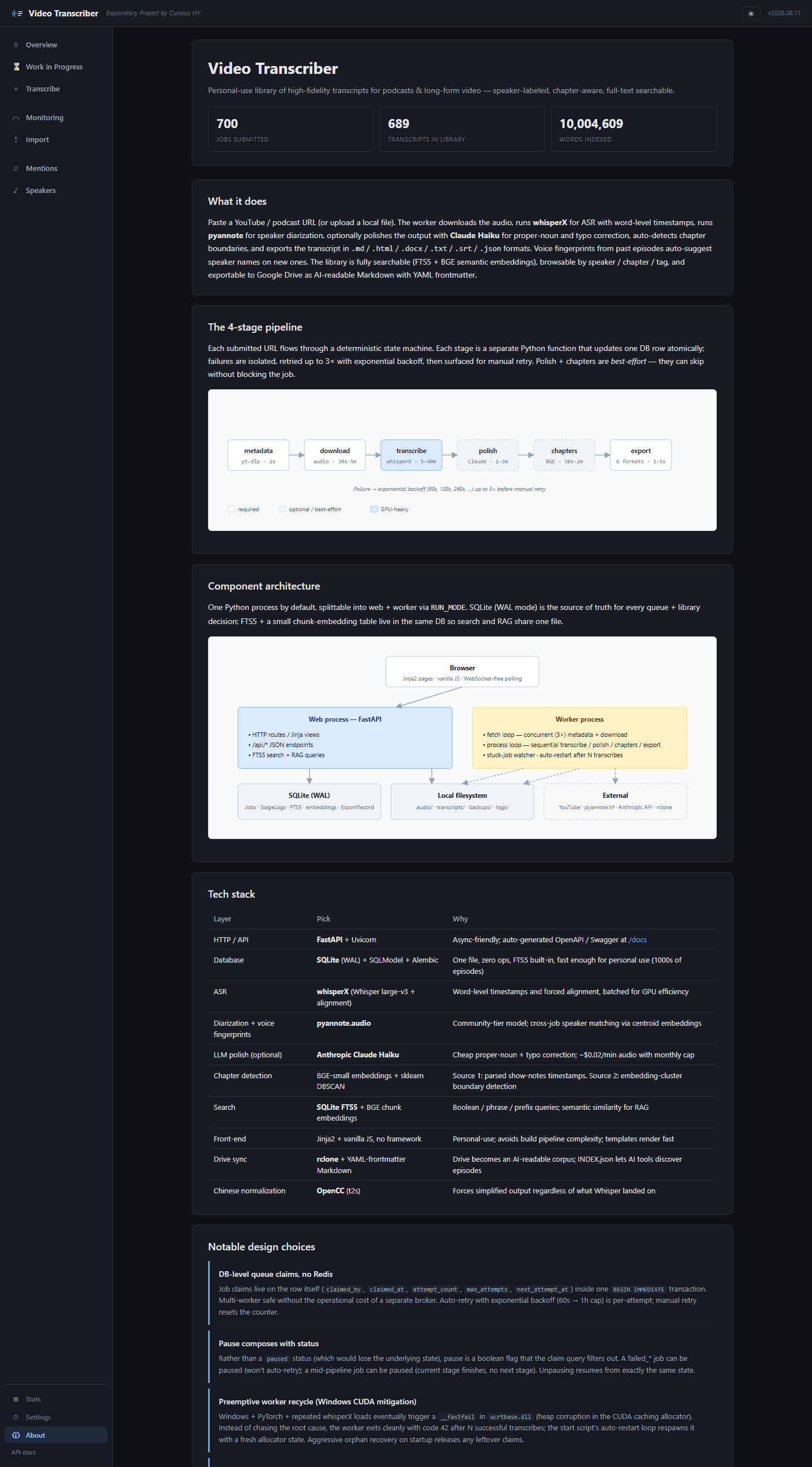
What it does
Multi-source ingest Channels & playlists
Paste a URL, scan a YouTube channel or playlist, or upload a local file. The channel scan returns thumbnails + dedup status against the existing library, so you never accidentally re-transcribe an episode you already have.
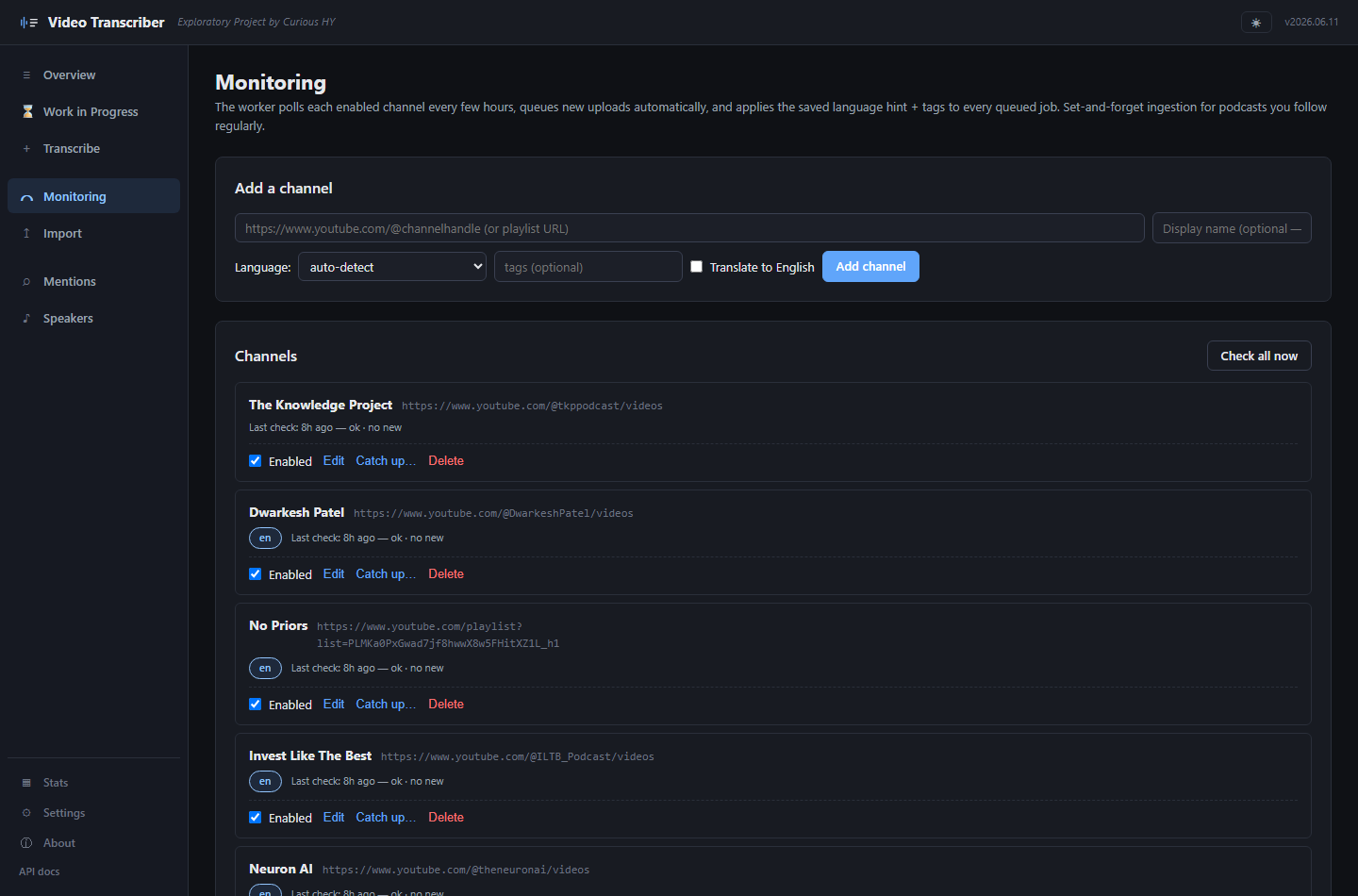
Channel monitoring with backfill Set & forget
Add a channel and the worker polls every few hours, queuing new uploads automatically with the channel's saved language hint + tags. A "Catch up" flow pulls historical episodes since any calendar-anchored date (start of this month, start of last year, etc.) with a preview of the candidate list and estimated cost before commit.
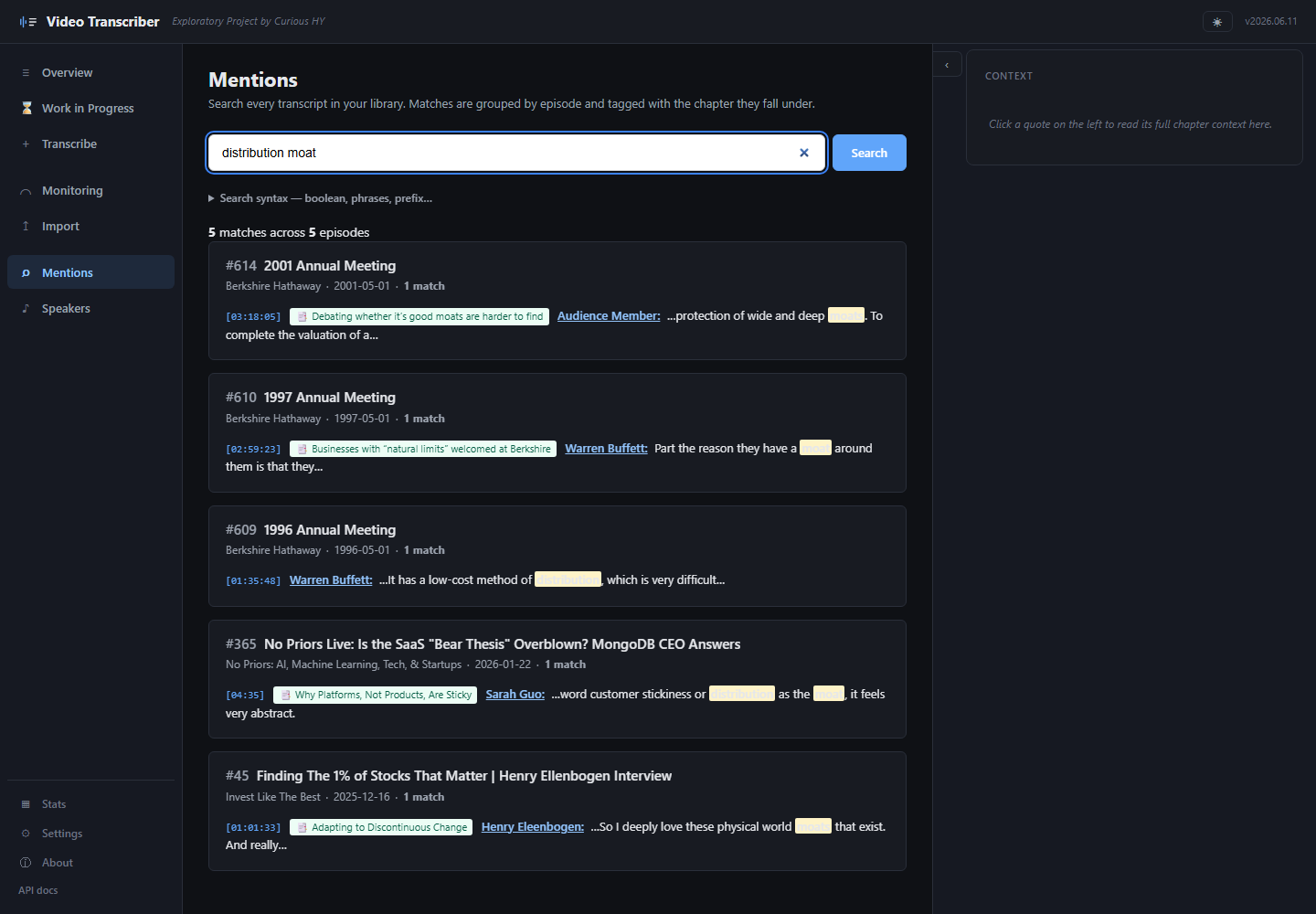
Cross-library search Mentions
Boolean queries, phrase matching, NOT operators. Results carry chapter context, speaker attribution, and timestamped links — so a single query can return five matches across five episodes spanning thirty years, each one jumping you straight to the moment it was said.
Claude integration via MCP 11 tools
The library exposes 11 tools to Claude Desktop and Claude Code over a streamable-HTTP MCP server — search transcripts, get full transcripts, find speaker quotes, list episodes similar to one I liked, return chapter summaries. Plug it in and you can ask grounded questions over years of content, with citations.
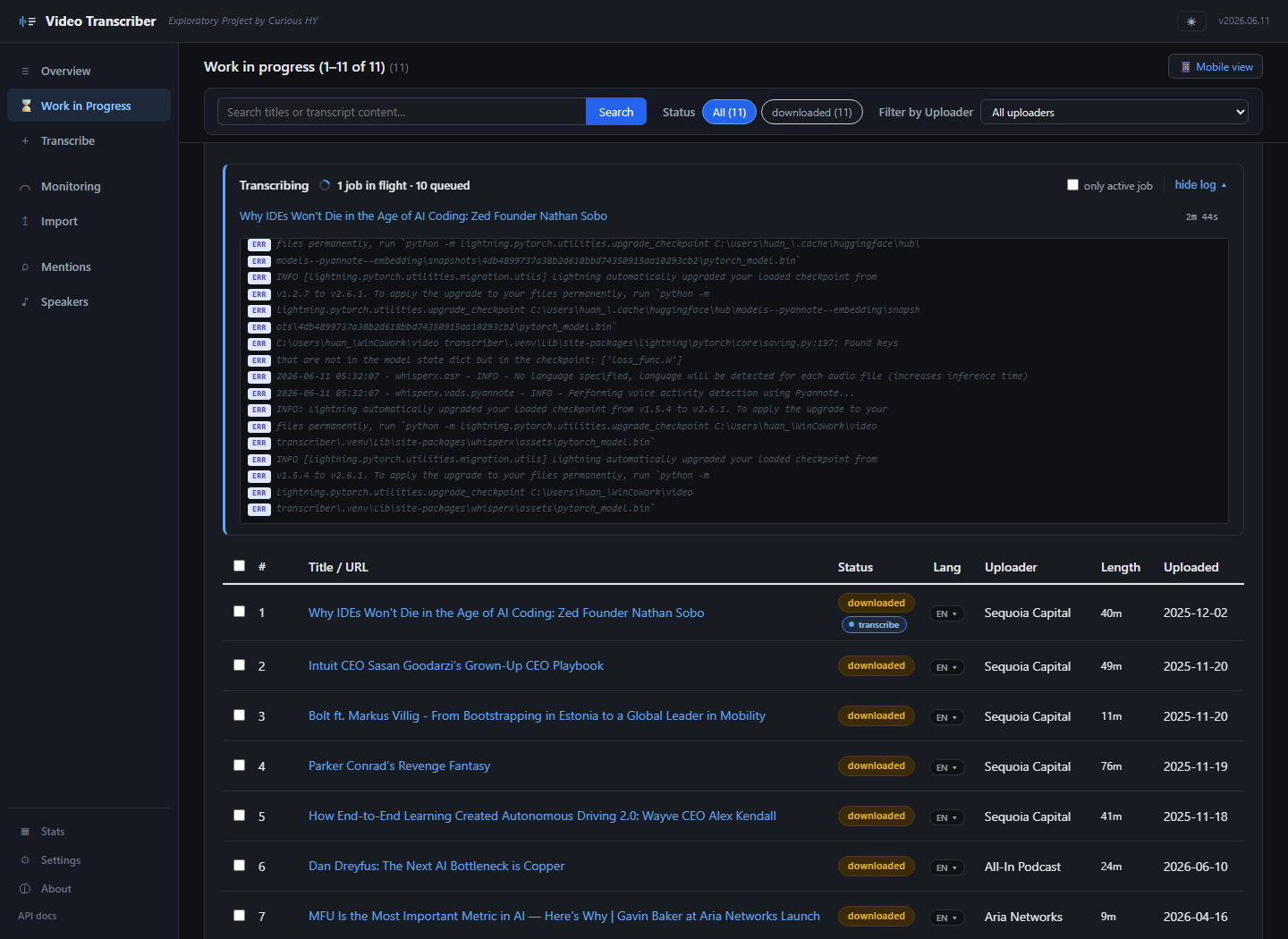
Live operational visibility WIP
While a transcription runs, the Work in Progress page shows elapsed time, the active stage, and a color-coded log tail with stderr from whisperX and pyannote merged inline. A focus filter shows only lines about the currently-running job, with timestamp-aware cutoffs so old stderr from a previous job doesn't contaminate the view.
Speaker recognition across episodes Voiceprints
Diarization splits each episode into anonymous voices; a persistent voiceprint database then matches those voices against everyone it has heard before. When I edit a transcript, the box suggests the likely name — "this sounds like Charlie Munger" — for a one-click confirm. Every confirmation feeds back into the database, so identification gets more accurate the more I transcribe. It's the difference between "Speaker 2 said this" and a library where the same person is correctly attributed across hundreds of episodes.
Speaker priority for search ranking Curated weights
A per-speaker credibility layer biases MCP search results without hard-filtering them. Mark Charlie Munger as high and his quotes float to the top for any query he's relevant to; mark a host whose phrasing you find unhelpful as low and they sink a little. It changes the order results come back in, not what's included.
How it's built
One Python process (FastAPI + Jinja2) by default, splittable into separate web and worker processes via an env flag for production-style isolation. SQLite (WAL mode) is the source of truth for every queue and library decision. FTS5 + a small chunk-embedding table live in the same DB so search and RAG share one file. The transcribe pipeline is a deterministic 6-stage state machine: metadata → download → transcribe (whisperX + pyannote) → polish (Claude Haiku, optional) → chapter detection → multi-format export.
Notable engineering decisions
Windows CUDA fastfail mitigation
After ~5 consecutive transcribes, the worker would die with exit code 0xc0000409
(Windows native fastfail) — almost certainly heap corruption in the CUDA caching allocator.
Solved with a preemptive recycle after N successful transcribes plus an auto-restart loop
in the launcher script. Stderr is teed to a rotating file so the next crash is at least diagnosable.
Watcher + restart pair survives essentially every native crash mode I've encountered in a year of
running.
Two-process MCP server
The MCP HTTP server runs in its own long-lived Python process, separate from the transcription app. The transcribe app self-recycles every N jobs (see above); the MCP server only reads the DB and embeds short queries (no CUDA), so it stays up indefinitely. Speaker-credibility edits don't need a restart either — each process re-reads the config file when its modified-time changes, so an edit made in one is picked up by the other on its next query.
The 6-hour timeout false-positive
The stuck-job watcher used to kill any transcribe stage that ran longer than 6 hours. Long-form
audio (Acquired's 4-hour episodes) plus pyannote diarization legitimately needs 9–10h on consumer
GPU. Watcher tripped on real work, the orphaned thread finished anyway, and the row carried a
ghost "timed out" error message into the library. Switched to a duration-scaled budget
(max(2h, audio_length × 2.5)) and made a successful finish clear the stale error.
The watcher only needs to catch genuine hangs, and a flat 6 hours was just too aggressive for
the longest episodes.
Audio retention with auto-archive
Raw audio averages ~70MB per episode; multiply by 600+ and it adds up. The transcript JSON has
everything needed for re-render and (if needed) re-diarization with a newer model, so the mp3
itself is auto-deleted N days after a successful transcribe. The /stats
page surfaces what's eating disk so the cleanup loop's effect is verifiable, not just a faith
claim.
Stack
Screens
Now that the words have done their job — here's what it actually looks like.
The app
Architecture
Final remarks
It's amazing how vibe coding has totally changed my perspective on what's possible — putting into motion what would once have taken teams months to accomplish. The ability to leverage open-source knowledge and code bases, without even needing to be technical, is an entire paradigm shift. Ideas rule paramount.
Keen to exchange ideas and push the realms of potential — reach me on LinkedIn.